
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- NoSQL
- 깃허브
- VMware
- 정처기
- 레디스
- Redis
- 스프링 시큐리티
- 영속성 컨텍스트
- github
- JPA
- document database
- 정보처리기사
- 동적계획법
- 스프링부트
- 분할정복
- 캐시
- MongoDB
- spring security
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
- in-memory
- 게시판
- 자바의 정석
- SQL
- 실행 컨텍스트
- 호이스팅
- 스프링 부트
- 이벤트루프
- 다이나믹프로그래밍
- Spring Boot
- sqld
- Today
- Total
FreeHand
[MongoDB] 몽고디비 입문 본문

시작하며
3년 전에 학교 수업에서 웹 애플리케이션을 만들어서 발표하는 과제가 있었다. 그때 다른 팀에서 MongoDB를 사용했었다.
교수님: 왜 MongoDB를 사용한거니? MongoDB가 뭔데? 알고 쓴거니?
학생: 어... 유튜브에서 MongoDB로 만들길래 그냥 따라 했어요.
위 대화가 아직도 생생하게 기억난다.
지금 다시 생각해 보면 MongoDB를 사용한 것이 좋은 선택인지 아닌지 보다도 서비스의 요구사항과 MongoDB의 특징을 전혀 모르고 이유도 없이 그냥 사용했다는 것이 교수님 입장에서는 답답했을 것 같다.
이 포스팅에서 정리하는 정도의 내용이라도 알았더라면 그 학생은 교수님의 회사로 간택당했을 수도 있지 않았을까...
MongoDB 소개
MongoDB는 Document Database인 NoSQL이다.
용어를 하나씩 설명하자면
NoSQL은 관계형 데이터베이스가 아닌, 즉 테이블 구조가 아닌 데이터베이스를 의미한다.
NoSQL은 Document Store(MongoDB), Key-Value Store(Redis), Wide-Column Store(HBase), Graph Store 등이 있다.
Document는 JSON 객체와 유사하게 field-value 쌍으로 구성된 데이터 구조를 말한다.

MongDB의 장점
- 스키마가 자유롭다(요구사항에 맞게 수용하기 쉽다)
- Document 구조의 특성상 Join 없이 조회하여 속도가 빠르다
- 다양한 종류의 인덱스를 제공한다
- HA와 Sharding 솔루션을 제공하여 Scale out 확장이 쉽다
MongoDB의 단점
- 정규화를 통해 데이터 중복을 피하는 RDB와 달리 데이터 중복이 발생할 수 있다
- 스키마 설계를 잘해야 성능저하를 피할 수 있다
지금은 일단 저런 장단점이 있다는 것을 보고 넘어가면 된다.
이후에 나오는 내용을 보고 다시 장단점을 보면 그때 이해가 된다.
MongoDB의 데이터 구성 요소는 다음과 같다.
- Collection
- RDB의 Table과 같은 개념
- 동적 스키마를 갖고 있어서 스키마를 수정하려면 필드 값을 추가/수정/삭제하면 된다.
- Collection 단위로 인덱스를 생성할 수 있다.
- Collection 단위로 Shard를 나눌 수 있다.
- Document
- RDB의 Row와 같은 개념
- JSON 형태로 표현하고 BSON(Binary JSON) 형태로 저장한다.
- 모든 Document에는 _id 필드가 있고, 없는 상태로 생성하면 ObjectId 타입의 고유한 값을 지정한다.
- 생성 시 상위 구조인 Database나 Collection이 없으면 먼저 생성하고 Document가 생성된다.
- 최대 크기는 16MB이다.
- Field
- RDB의 Column과 같은 개념
뭔가 많은 설명이 있었지만 일단 처음엔 이것만 알면 된다.
Collection = Table
Document = Row
Field = Column
Replication
DB를 공부하면 빠짐없이 등장하는 복제에 대한 내용이 MongoDB에도 있다.
복제는 장애가 발생하면 복제본을 통해 서비스를 정상적으로 제공하는데 목적이 있다.
따라서 고가용성 또는 HA라고도 부른다.
MongoDB는 고가용성(HA)을 확보하기 위해 Replica Set으로 구성할 수 있다.


Replica Set은 원본인 Primary와 복제본인 Secondary로 구성된다.
Replica Set의 멤버들은 다음과 같은 특징이 있다.
Primary
- Read/Write 요청을 모두 처리할 수 있다.
- Write 요청을 처리할 수 있는 유일한 멤버이다.
- Replica Set에 하나만 존재할 수 있다.
Secondary
- Read 요청만 처리할 수 있다.
- 복제를 통해 Primary와 동일한 데이터를 갖는다.
- Replica Set에 여러 개 존재할 수 있다.
처음에는 왼쪽 그림처럼 Primary가 모든 Read/Write 요청을 처리한다.
Read Preference 설정을 하면 오른쪽 그림처럼 Primary는 Write 요청만 처리하고 Secondary가 Read 요청을 처리한다.

Replica Set의 멤버들은 서로 Hearbeat를 보내서 서로 잘 살아있는지 확인한다.
만약 Primary가 응답이 없으면 멤버들의 과반수 이상 투표를 받은 Scondary가 새로운 Primary가 된다.
따라서 원활한 투표를 위해 Replica Set의 멤버는 3개 이상 홀수로 구성하는 것이 좋다고 한다.


투표에 참여할 수 있는 멤버는 Primary와 Secondary 말고 Arbiter도 있다.
Arbiter는 데이터는 갖고 있지 않고 투표용으로만 사용된다.
그러나 Arbiter를 포함하는 PSA 구조는 권장되는 방식은 아니라고 한다.
Secondary가 죽었을 경우, PSS는 다른 Secondary가 Read 요청을 수행할 수 있지만 PSA는 Arbiter에 데이터가 없어서 Read 요청을 수행할 수 없기 때문에 Primary가 Read 요청까지 처리해야 해서 부담이 늘기 때문이다.
Sharding
Replication이 HA를 위한 솔루션이라면 Sharding은 분산처리를 위한 솔루션이다. 아래 내용을 보면 알겠지만 각 Shard가 replica set으로 구성되어서 Sharding은 HA도 보장한다.
Sharding이란 하나의 큰 데이터를 여러 장비에 분할하는 것을 의미한다.

Sharded Cluster는 다음 요소들로 구성된다.
- Shard: 분할된 데이터의 모음. 모든 shard는 replica set으로 구성된다.
- Mongos(Router): Shard에 쿼리를 전달하고 결과를 merge 해서 사용자에게 반환하는 라우터 역할
- Config Server: Cluster의 메타데이터를 갖고 있다. Replica Set으로 구성된다.
각 요소들이 작동하는 순서는 다음과 같다.
1. 사용자가 application으로 요청을 보냄
2. mongos가 config server에서 meta data를 확인해서 찾고자 하는 데이터가 어떤 shard에 있는지 찾고 mongos가 해당 shard에서 데이터를 찾아서 반환함

Sharding은 Collection 단위로 가능하다.
그러나 모든 collection이 꼭 여러 shard에 분산되어 저장될 필요는 없다.
메타성 데이터는 크기가 작고 자주 조회되므로 분산하지 않는 것이 더 좋다고 한다.
Sharding의 장점
- 용량 한계를 극복할 수 있다.
- 데이터의 규모와 부하가 커도 처리량이 좋다.
- 고가용성을 보장한다.
Sharding의 단점
- 관리가 비교적 복잡하다.
- Replica Set과 비교해서 쿼리가 느리다.
- 데이터가 분산되어 있어서 각 shard에서 찾고 merge 하는 과정이 필요하다.
Sharding 전략
1. Ranged Sharding

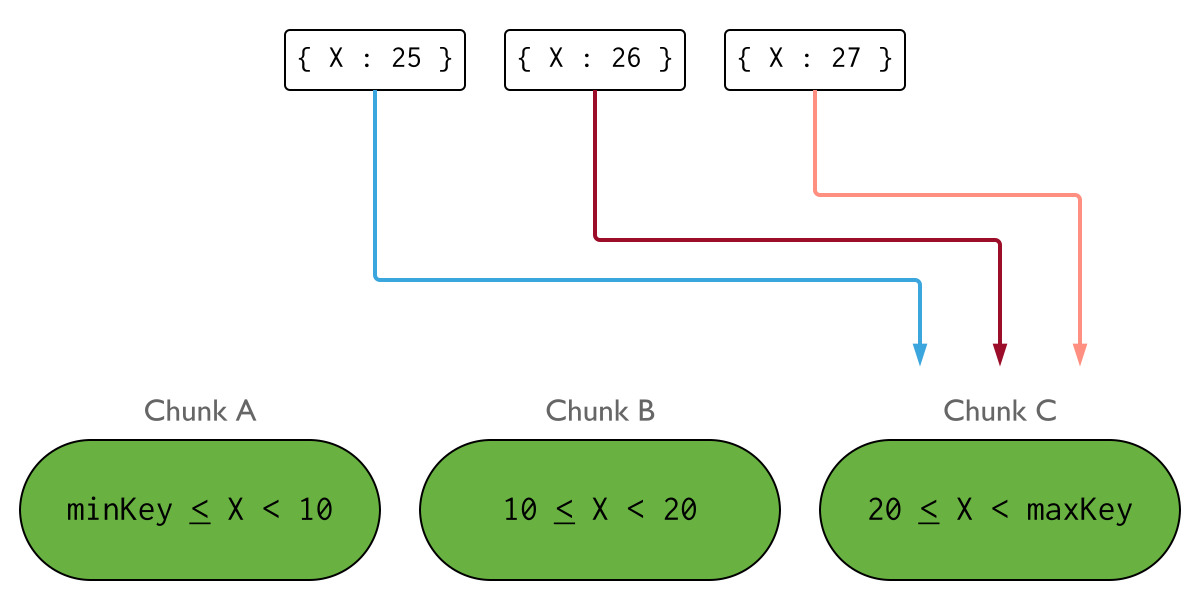
Shard key의 값을 기준으로 sharding 한다. 오른쪽 그림처럼 특정 shard에 데이터가 몰릴 수 있다는 단점이 있다.
따라서 Hash Sharding이 불가능할 때, 타겟 쿼리가 필요할 때(빠른 조회), 데이터가 범위 별로 균등할 때 사용한다.
2. Hashed Sharding

shard key의 값을 hash 함수에 적용해서 반환하는 값을 기준으로 sharding 하는 방법이다. 균등하게 분산되는 장점이 있으나 범위 검색에는 약하다. 가장 권장되고 많이 사용되는 방법이라고 한다.
3. Zone Sharding

주로 글로벌하게 지역별로 데이터를 분산시켜야 하는 경우 ip별로 zone구성해서 사용한다.
Replica Set vs Sharded Cluster
| 배포형태 | 장점 | 단점 |
| Replica Set | 운영이 쉽다 장애 발생시 문제해결 및 복구가 쉽다 서버 비용이 적다 성능이 좋다 개발시 설계가 용이 |
Write에 대한 분산이 불가능 |
| Sharded Cluster | Scale-Out이 가능하다 Write에 대한 분산이 가능하다 |
Replica Set의 모든 장점이 상대적인 단점 |
가능하면 Replica Set으로 배포하는 것이 좋으나 서비스의 요구사항에 맞게 선택하는 것이 바람직하다고 한다.
서비스의 요구사항이 Replica Set으로 충족하지 못할 경우 Sharded Cluster를 고려할 수 있다.
ex)
- 용량이 부족한 경우 => sharding
- 용량은 남지만 write 요청이 많은 서비스 => sharding (replication은 primary가 부담)
마치며
이번에는 MongoDB가 무엇인지 MongoDB의 전반적인 내용을 알아봤고 다음에는 MongoDB를 실제로 사용하는 방법과 스프링에서는 어떻게 활용하는지 공부하고 정리할 예정이다.
RDB만 잘 사용해도 충분히 개발할 수 있겠지만 NoSQL도 알아두면 언젠가 RDB로 해결하기 힘든 문제를 만났을 때 해결책으로 떠올릴 수 있을 것 같다.
이미지 출처: MongoDB 공식문서 What is MongoDB? - MongoDB Manual v7.0
'Database' 카테고리의 다른 글
| 옵티마이저와 실행계획 (4) | 2024.09.24 |
|---|---|
| [Redis] 처음 만난 레디스 2 (1) | 2024.06.17 |
| [Redis] 처음 만난 레디스 1 (2) | 2024.06.15 |
| [MySQL] 데이터 타입과 형 변환 (0) | 2023.11.05 |
| [MySQL] WITH절과 CTE (0) | 2023.11.05 |



