
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 레디스
- 캐시
- 스프링 부트
- in-memory
- spring security
- 이벤트루프
- Redis
- 동적계획법
- 스프링 시큐리티
- JPA
- 다이나믹프로그래밍
- 호이스팅
- SQL
- 게시판
- 실행 컨텍스트
- MongoDB
- 깃허브
- github
- 자바의 정석
- 스프링부트
- NoSQL
- 분할정복
- VMware
- 정처기
- document database
- 영속성 컨텍스트
- Spring Boot
- 정보처리기사
- sqld
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
- Today
- Total
FreeHand
[Redis] 처음 만난 레디스 1 본문

시작하며
백엔드 개발자에게 캐시는 중요한 개념이다. DB에 있는 데이터에 접근하는 것은 결국 디스크 I/O가 발생하는 것이고 이는 매우 느리기 때문에 대용량 요청이 들어올 경우 병목현상의 원인이 된다. 이를 부분적으로 해결하기 위한 방법으로 캐시를 활용할 수 있고 대표적으로 많이 사용하는 Redis의 특징과 데이터 타입에 대해 알아본다.
Redis의 특징
Redis는 흔히 사용하는 RDB와 몇 가지 차이가 있다.
우선 SQL을 사용하는 RDB와 달리 SQL을 사용하지 않는 Key-Value 형태의 저장소인 NoSQL이다.
따라서 복잡한 쿼리를 작성할 필요가 없고 Hash를 이용해 값을 읽으므로 속도가 더 빠르다.
그러나 쿼리를 사용하지 않는 것은 범위 검색과 같은 복잡한 질의가 불가능하다는 단점이 되기도 한다.
또한 Redis는 데이터를 디스크가 아닌 메모리에 저장하는 In-memory DB이기 때문에 RDB에 비해 속도가 매우 빠르다.
그러나 메모리의 휘발성으로 인해 데이터를 손실할 위험이 있어 백업과 회복 등 영속성 확보에 신경을 써야 한다.
이러한 특징을 가진 Redis는 Cache, Message Queue 등으로 사용된다.
Redis 설치 및 실행
나는 윈도우 OS에서 도커 이미지로 간단하게 redis를 설치해서 사용하려고 한다.
cmd에서 아래 명령을 실행한다.
1. redis 도커 이미지 다운로드
> docker pull redis별도로 버전을 지정하지 않으면 최신 버전으로 설치된다.
2. 도커 이미지로 컨테이너 실행
> docker run --name my-redis -d -p 6379:6379 redis
> docker ps
3. 도커 컨테이너 안에서 쉘 실행
> docker exec -it my-redis /bin/sh
4. 쉘에서 redis-cli 실행
# redis-cli
5. Redis 명령 사용
Redis의 데이터 타입
Strings
- 가장 기본적인 데이터 타입으로 가장 많이 사용되는 타입
- 바이트 배열을 저장(binary-safe)
- 바이너리로 변환할 수 있는 모든 데이터를 저장 가능(JPG 등)
- 최대 크기는 512MB

myname이라는 key에 jin이라는 value를 지정하고 값을 가져오는 과정이다.
Strings 타입을 사용할 때 다음 명령어들을 주로 사용한다.
- SET
- 특정 키에 문자열 값을 저장
- SET key value
- ex) SET myname jin
- GET
- 특정 키의 문자열 값을 얻음
- GET key
- ex) GET myname
- INCR
- 특정 키의 값을 Integer로 취급하여 1 증가시킴
- INCR key
- ex) INCR mycount
- DECR
- 특정 키의 값을 Integer로 취급하여 1 감소시킴
- DECR key
- ex) DECR mycount
- MSET
- 여러 키에 대한 값을 한 번에 저장
- MSET key1 value1 key2 value2
- ex) MSET name jin age 26
- MGET
- 여러 키에 대한 값을 한 번에 얻음
- MGET key1 key2
- ex) MGET name age
Lists
- value에 linked-list 자료구조가 저장되는 타입
- 스택과 큐로 사용 가능
Lists의 주요 명령어는 다음과 같다.
- LPUSH
- 리스트의 왼쪽에 값을 추가
- LPUSH key(list name) value
- ex) LPUSH mylist apple
- RPUSH
- 리스트의 오른쪽에 값을 추가
- RPUSH key(list name) value
- ex) RPUSH mylist banana
- LLEN
- 리스트의 아이템 개수를 반환
- LLEN key(list name)
- ex) LLEN mylist
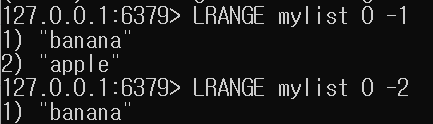
- LRANGE
- 리스트의 특정 범위를 반환
- LRANGE 시작 끝
- ex) LRANGE 0 -1 (-1은 오른쪽 끝)
- LPOP
- 리스트의 왼쪽 값을 삭제하고 반환
- LPOP key(list name)
- ex) LPOP mylist
- RPOP
- 리스트의 오른쪽 값을 삭제하고 반환
- RPOP key(list name)
- ex) RPOP mylist

Sets
- 순서가 없는 유일한 값의 집합
- 검색이 빠름
- 개별 접근을 위한 인덱스가 없음
- 집합 연산이 가능
Sets의 주요 명령어
- SAAD
- Set에 데이터 추가
- SADD key(set name) value
- ex) SADD myset apple
- SREM
- Set에서 데이터 삭제
- SREM key(set name) value
- ex) SREM myset apple
- SCARD
- Set에 저장된 아이템의 개수를 반환
- SCARD key(set name)
- ex) SCARD myset
- SMEMBERS
- Set에 저장된 아이템들을 반환
- SMEMBERS key(set name)
- ex) SMEMBERS myset
- SISMEMBER
- 특정 값이 Set에 있는지를 반환
- SISMEMBER key(set name) value
- ex) SISMEMBER myset apple
Hashes
- value에 field-value 쌍을 저장하는 타입
- 여러 필드를 가진 객체를 저장하는 것으로 생각할 수 있음 (String 타입과의 차이점)
- HINCRBY 명령어를 사용해 카운터로 활용 가능
주요 명령어
- HSET
- 한 개 이상의 필드에 값을 저장
- HSET key(hash name) field1 value1 field2 value2
- ex) HSET user1 name jin age 26
- HGET
- 특정 필드의 값을 반환
- HGET key(hash name) field
- ex) HGET user1 name
- HMGET
- 한 개 이상의 필드 값을 반환
- HMGET key(hash name) field1 field2
- ex) HMGET user1 name age
- HINCRBY
- 특정 필드의 값을 Integer로 취급하여 지정한 숫자를 증가시킴
- HINCRBY key(hash name) field 증가시킬 숫자
- ex) HINCRBY user1 viewcount 1
- HDEL
- 한 개 이상의 필드를 삭제
- HDEL key(hash name) field1 (field2)
- ex) HDEL user1 name age
SortedSets
- 유일한 값의 집합
- 각 값은 연관된 score를 갖고 정렬되어 있음
- 순위 계산, 리더보드 구현 등에 활용
주요 명령어
- ZADD
- 한 개 이상의 값을 추가 또는 업데이트
- ZADD key(set name) score1 value1 score2 value2
- ex) ZADD myrank 10 apple 20 banana
- ZRANGE
- 특정 범위의 값을 반환
- ZRANGE key(set name) 시작 끝
- ex) ZRANGE myrank 0 1
- ZRANK
- 특정 값의 위치(순위)를 반환
- ZRANK key(set name) value
- ex) ZRANK myrank apple
- ZREVRANK
- ZRANK와 정렬 기준만 다름
- 내림차순 정렬 기준으로 위치 순위 반환
- ZREM
- 한 개 이상의 값을 삭제
- ZREM key(set name) value
- ex) ZREM myrank apple
Bitmaps
- 비트 벡터를 사용해 여러 개의 Set을 공간 효율적으로 저장
- 비트 연산이 가능
주요 명령어
- SETBIT
- 비트맵의 특정 오프셋에 값을 변경
- SETBIT key(bitmap name) offset 0 또는 1
- ex) SETBIT visit 10 1
- GETBIT
- 비트맵의 특정 오프셋의 값을 반환
- GETBIT key(bitmap name) offset
- ex) GETBIT visit 10
- BITCOUNT
- 비트맵에서 set(1) 상태인 비트의 개수를 반환
- BITCOUNT key(bitmap name)
- ex) BITCOUNT visit
- BITOP
- 비트맵들 간의 비트 연산을 수행하고 결과를 비트맵에 저장
- BITOP 연산 결과비트맵 연산비트맵1 연산비트맵2
- ex) BITOP AND result today yesterday
HyperLogLog
- 유니크한 값의 개수를 효율적으로 얻을 수 있음
- 확률적 자료구조로서 오차가 있으며, 매우 큰 데이터를 다룰 때 사용
주요 명령어
- PFADD
- HyperLogLog에 값을 추가
- ex) PFADD visit Jay Peter Jane
- PFCOUNT
- HyperLogLog에 입력된 값들의 카디널리티를 반환
- ex) PFCOUNT visit
- PFMERGE
- 다수의 HyperLogLog를 병합
- ex) PFMERGE result visit1 visit2
마치며
Redis를 처음 공부하며 Redis의 특징과 데이터 타입에 대해 알게 되었다.
그러나 Redis를 실제로 사용할 때 잘 사용하려면 공부해야 할 내용이 엄청 많다고 느꼈다.
알아두면 많은 곳에서 유용하게 사용할 것 같아서 Redis에 대해서는 더 공부할 예정이다.
'Database' 카테고리의 다른 글
| [MongoDB] 몽고디비 입문 (0) | 2024.06.22 |
|---|---|
| [Redis] 처음 만난 레디스 2 (1) | 2024.06.17 |
| [MySQL] 데이터 타입과 형 변환 (0) | 2023.11.05 |
| [MySQL] WITH절과 CTE (0) | 2023.11.05 |
| [MySQL] DELETE (0) | 2023.11.01 |



